首页 > 编程笔记
Celery框架入门教程(简明版)
通常,Python 程序运行过程中,如果要执行耗时的任务,但又不希望主程序被阻塞,常见的方法是采用多线程。但是当并发量过大时,多线程压力很大,必须要用线程池来限制并发个数,而且多线程对共享资源的使用也很麻烦。
我们也可以使用协程,但是协程是在同一线程内执行的,如果一个任务本身需要执行很长时间,而不是因为等待 IO 被挂起,那其他协程照样无法运行。
Celery 采用多进程方式,能够有效利用多核 CPU,并且 Celery 封装了常见任务队列的各种操作,我们可以用 Celery 提供的接口快速实现并管理一个分布式的异步任务队列。
Celery 具备如下几个显著的优点。
Celery 本身不提供消息代理服务,但是可以集成第三方提供的消息中间件。常见的 Brokers 有 RabbitMQ、Redis、ZooKeeper 等,但适用于生产环境的只有 RabbitMQ 和 Redis。
Celery 默认支持 Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy 等方式存储。
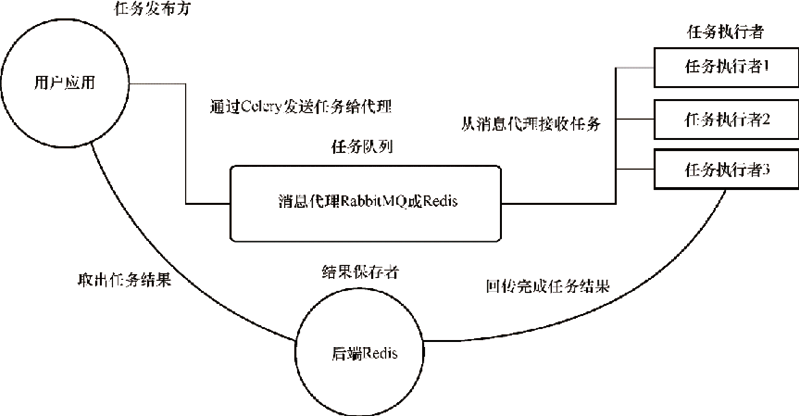
图1:Celery 的架构
Celery 的基本工作就是管理任务,分配任务到不同的服务器,并且取得结果。
Celery 本身不能解决服务器之间的通信,所以,RabbitMQ 或 Redis 作为一个消息队列管理工具,与 Celery 集成,负责处理服务器之间的通信任务。
Celery 没有消息存储功能,它需要介质,如 RabbitMQ、Redis、MySQL 和 MongoDB。
在图1中,用户应用(任务发布方)发布任务到 Broker,通常使用 RabbitMQ 或 Redis 来存储任务,然后调用任务执行单元进行工作,最后把结果通过后端(如 Redis)来存储,最后用户应用根据需要取出结果。
Celery 的主要应用场景如下:
APScheduler 提供了多种不同的调度器,方便开发人员根据自己的实际需要使用,同时提供了不同的存储机制,方便与 Redis 数据库等第三方的外部持久化工具协同工作。
总之,APScheduler 功能强大且非常易用。
我们先安装 Redis,重点是安装必要的 Python 库,可以通过命令行也可以直接在 PyCharm 中下载安装。本教程采用的 Celery 版本是 5.2.3。
我们可以通过命令行方式下载和安装指定版本:
flower 还提供了 REST API 用于第三方应用直接触发任务执行、获取任务执行结果等,这极大地扩展了 Celery 的应用范围,例如一个 Java 应用可以通过 flower 的 REST API 使用 Celery 的异步任务系统。
Celery 支持多种的数据序列化方式,常见的数据序列化方式如表2所示。通常,为了保持跨语言的兼容性和速度,我们一般采用 msgpack 或 JSON 方式。
下面我们使用 Redis 来展示,Redis 在使用的时候充当两个角色,一个是消息中间件,另一个是存储结果的数据库。
基本使用主要有如下5个步骤。
1) 创建项目celeryDemo。
2) 创建异步任务执行文件 celery_task,文件内容如代码清单3所示。
代码清单3:celery_task
3) 使用命令启动Celery:
4) 执行测试函数。建立一个文件,使用如下代码测试 Celery 异步函数:
5) 异步获取结果如下:
1) 装饰器 @app.task 实际上将一个正常的函数修饰成一个 Task 对象,所以这里可以给修饰器加上参数来决定修饰后的 Task 对象的属性。
我们先让被修饰的函数成为 Task 对象的绑定方法,这相当于被修饰的函数成了 Task 的实例方法,可以调用 self 获取当前 task 实例的很多状态和属性。
2) 任务执行后,根据任务状态执行不同操作,这需要复写 Task 的 on_failure、on_success 等方法。示例如下:
3) 任务状态回调。
在实际场景中,获得任务状态是很常见的需求,当执行耗时时间较长的任务时,想获得任务的实时进度,需要自定义一个任务状态来说明进度并手动更新状态,从而告诉回调函数当前任务的进度。
下面示例展示了一个长时间运行的任务,用户通过浏览器启动一个或者多个长时间运行的任务,通过浏览器页面可以查询执行中的所有任务的状态,页面会显示每一个任务的状态消息,当任务完成时会显示任务的执行结果。
图2是示例项目 myCelery 的项目结构。
图2:myCelery 的项目结构
在安装相关的依赖和 Redis 中间件后,结合 Flask 使用 Celery,主要有如下5步。
1) 配置并实例化 Celery 和 Flask 对象,并做配置绑定。Flask 与 Celery 整合不需要任何插件,Flask 应用使用 Celery 只需要初始化 Celery 客户端即可,示例如代码清单4所示。
代码清单4:celeryApp
另外,Celery 的其他配置可以直接用 celery_app.conf.update (flask_app.config) 通过 Flask 的配置直接传递。
2) 用实例化的对象去关联执行任务的方法,通常通过 Python 的装饰器实现。任何作为后台异步任务的函数只需要用 @celery.task 装饰器装饰即可,即在需要异步执行的方法上使用 @celery.task 装饰器。示例如代码清单5所示。
代码清单5:task
对于这个任务,通过在 Celery 装饰器中添加 bind=True 参数,让 Celery 发送一个 self 参数到自身,并使用它(self)来记录状态更新。self.update_state() 调用 Celery 如何接受这些任务更新。
Celery 有一些内置的状态,如 STARTED、SUCCESS 等,也支持自定义状态。代码中使用一个叫作 PROGRESS 的自定义状态,还可以有一个附件的元数据,该元数据是字典类型,包含目前和总的迭代数以及随机生成的状态消息。客户端可以使用这些数据来显示进度信息。每迭代一次休眠一秒,以模拟正在做一些工作。当循环退出,返回一个字典,这个字典包含更新迭代计数器、最后的状态消息和结果。
Celery 中常见的任务状态如表3所示。
3) 制作Flask的视图,演示调用和触发任务,并查看结果。通过 Flask,在浏览器中触发调用任务并查看异步执行的结果,这需要添加路由视图,示例如代码清单6所示。
代码清单6:webFlask
使用 apply_async(),我们可以添加参数给 Celery,告诉 Celery 如何执行后台任务,一个有用的参数就是要求任务在未来的某一时刻执行。例如,这个调用将安排任务在大约1分钟后运行:
正如我们所见,浏览器需要发起一个请求到 /longtask 来启动一个或多个任务。响应使用状态码 202 通常是在 REST API 中使用,用来表明一个请求正在进行中。
另外也添加了 Location 头,值为一个客户端用来获取状态信息的 URL。这个 URL 指向一个叫作 taskstatus 的 Flask 路由,并且通过动态的要素 task_id 来获取异步任务的执行状态。
在 Flask 应用中访问任务状态,路由 taskstatus 负责报告后台任务提供的状态更新。为了能够访问任务的数据,我们重新创建任务对象,该对象是 AsyncResult 类的实例,使用 URL 中的 task_id。
第一个 if 代码块是当任务还没有开始的时候(PENDING状态),在这种情况下暂时没有状态信息,需要手动制造一些数据。接下来,elif 代码块返回后台的任务的状态信息,任务提供的信息可以通过 task.info 获得。如果数据中包含键 result,则意味着这是最终的结果并且任务已经结束,需要把这些信息加入响应。最后,else 代码块是任务执行失败的情况,这种情况下 task.info 中会包含异常的信息。
4) 通过命令启动和验证。首先启动 worker 执行任务,命令如下:
Celery 任务启动成功如图3所示。
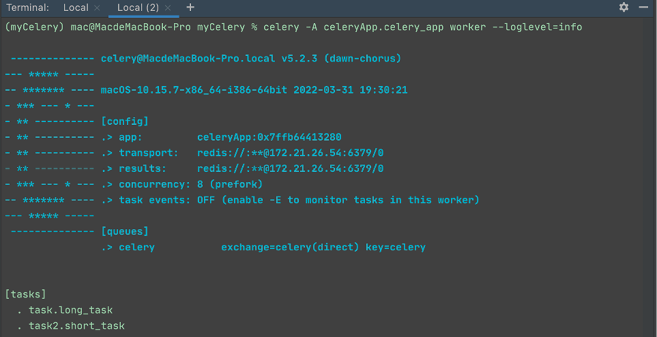
图3:Celery任务启动成功
在图3中,我们可以看到 transport 和 results 的地址信息,以及 tasks 下的两个任务。
其他常见的 Celery 命令:
若 Celery 的日志输出的配置,若想在任务中输出日志,最好的方法如下:
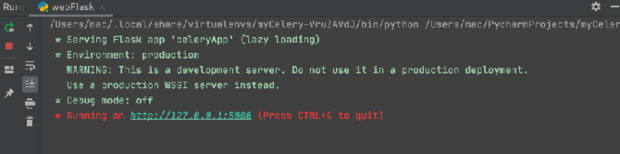
图4:Celery 结合 Flask 启动
接下来,通过浏览器触发 longtask 模拟的耗时任务,如图5所示,在浏览器输入地址后,会直接返回代码中预定义的消息。另外,此时已经触发异步任务,若点击多次,则会产生多条任务。
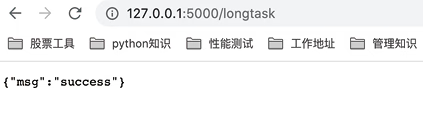
图5:在浏览器中触发 longtask 模拟的耗时任务
5) 监控和查看后台异步任务执行情况。我们可以进入 Redis,查看队列任务,发现有4条,使用 get 命令可以查看具体某一条任务的执行状态,如图6所示。
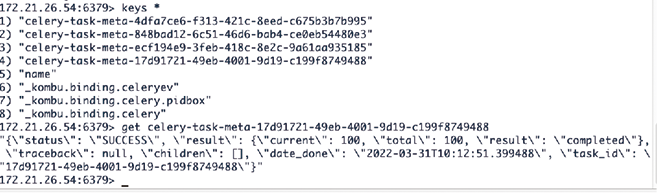
图6:查看队列任务
我们也可以通过浏览器查看,异步任务的3个时刻的执行状态如图7、图8和图9所示,可以发现 current 的值是动态变化的。
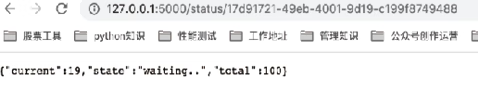
图7:异步任务状态1
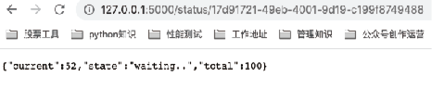
图8:异步任务状态2
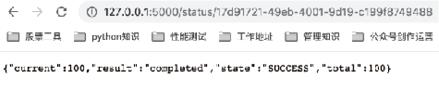
图9:异步任务状态3
最后,通过 flower 可以统筹监控所有的任务队列情况,执行命令如下:
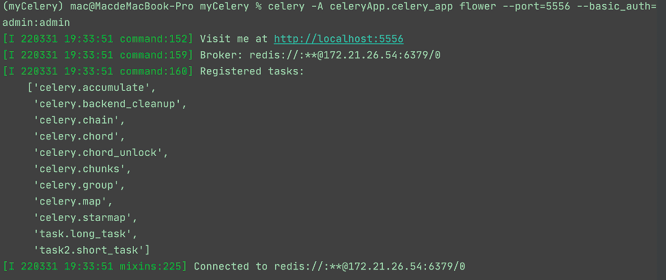
图10:监控任务队列
执行成功后,在浏览器中输入 http://localhost:5556,输入用户名和密码(admin/admin)登录,任务消费者如图11,任务名称如图12所示。
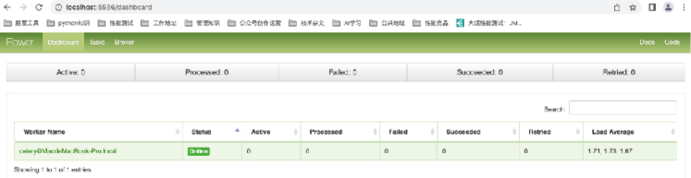
图11:任务消费者
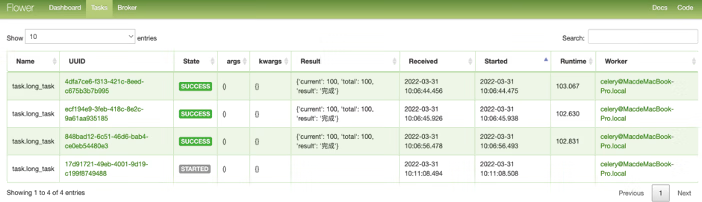
图12:任务名称
我们也可以使用协程,但是协程是在同一线程内执行的,如果一个任务本身需要执行很长时间,而不是因为等待 IO 被挂起,那其他协程照样无法运行。
一、Celery 简介
Celery 是一个基于 Python 开发的分布式异步消息队列,可以实现任务的异步处理,适合一些并行任务,可以实现 Web 业务代码的解耦。Celery 采用多进程方式,能够有效利用多核 CPU,并且 Celery 封装了常见任务队列的各种操作,我们可以用 Celery 提供的接口快速实现并管理一个分布式的异步任务队列。
Celery 具备如下几个显著的优点。
- 简单:熟悉 Celery 的工作流程后,配置使用简单。
- 高可用:当任务执行失败或发生连接中断,Celery 会自动尝试重新执行任务。
- 快速:一个单进程的 Celery 每分钟可处理上百万个任务,并且只需要毫秒级的延迟。
- 灵活:几乎 Celery 的各个组件都可以被扩展和定制。
1. 基本概念
虽然 Celery 是用 Python 实现的,但提供了其他常用语言的接口支持。在运行 Celery 之前,我们需要先明白几个概念。1) 消息代理(broker,也称消息中间件)
接受任务生产者发送的任务消息,存进队列并按序分发给任务消费者。Celery 本身不提供消息代理服务,但是可以集成第三方提供的消息中间件。常见的 Brokers 有 RabbitMQ、Redis、ZooKeeper 等,但适用于生产环境的只有 RabbitMQ 和 Redis。
2) 任务结果存储/后端(result store/backend)
顾名思义就是存储结果的地方,队列中的任务执行完的结果或者状态需要被任务生产者知道,所以需要一个存储这些结果的地方。Celery 默认支持 Redis、RabbitMQ、MongoDB、Django ORM、SQLAlchemy 等方式存储。
3) 任务执行者(worker)
即执行任务的消费者,通常会在多台服务器运行多个消费者来提高执行效率。4) 任务(task)
即我们想在队列中执行的任务,一般由用户或其他操作将任务入队,然后交由任务执行者处理。2. 架构设计
Celery 的架构如图1所示,主要由消息中间件、任务执行者和任务执行结果存储3部分组成。图1:Celery 的架构
Celery 的基本工作就是管理任务,分配任务到不同的服务器,并且取得结果。
Celery 本身不能解决服务器之间的通信,所以,RabbitMQ 或 Redis 作为一个消息队列管理工具,与 Celery 集成,负责处理服务器之间的通信任务。
Celery 没有消息存储功能,它需要介质,如 RabbitMQ、Redis、MySQL 和 MongoDB。
在图1中,用户应用(任务发布方)发布任务到 Broker,通常使用 RabbitMQ 或 Redis 来存储任务,然后调用任务执行单元进行工作,最后把结果通过后端(如 Redis)来存储,最后用户应用根据需要取出结果。
3. 应用场景
Celery 是一个强大的分布式任务队列的异步处理框架,它可以让任务的执行完全脱离主程序,甚至可以被分配到其他主机上运行。Celery 的主要应用场景如下:
- 我们在开发过程中经常遇到需要使用异步任务的场景,例如一个 Web 请求中有运行时间很长的业务运算(发送短信、邮件,消息推送,音视频处理等),如果不采用异步任务,会阻塞当前的任务请求,影响用户体验。此时,我们可以将耗时操作提交给 Celery 异步执行。
- 当有多种不同的任务,例如视频上传和压缩任务、照片压缩上传任务等,这些任务的优先级不同,需要使用不同的任务执行者去处理。Celery 可以定时执行某件事情,并在执行完成后通知任务生成者,也可以实现在运维场景下针对几百台机器批量执行某些命令或者任务。
关于 APScheduler
APScheduler 是一个基于 Quartz 的 Python 定时任务框架,它实现了 Quartz 的所有功能,提供了基于日期、固定时间间隔和 crontab 类型的任务,并且可以持久化任务。APScheduler 提供了多种不同的调度器,方便开发人员根据自己的实际需要使用,同时提供了不同的存储机制,方便与 Redis 数据库等第三方的外部持久化工具协同工作。
总之,APScheduler 功能强大且非常易用。
二、使用Celery
本教程我们先安装 Celery,再介绍 Celery 的参数,然后再讲解 Celery 的使用。1. 安装部署
Celery 涉及任务队列和结果存储,故需要安装 RabbitMQ 或 Redis,这里我们使用 Redis。我们先安装 Redis,重点是安装必要的 Python 库,可以通过命令行也可以直接在 PyCharm 中下载安装。本教程采用的 Celery 版本是 5.2.3。
我们可以通过命令行方式下载和安装指定版本:
# 安装Celery pip install celery==5.2.3 # 因为后端采用的是Redis,所以需要安装Redis pip install redis==4.2.0 # flower组件可以通过Web进行对Celery进行监控,但它不是必需的 pip install flower==1.0.0
Celery 监控
flower 是 Python 的用于监控 Celery 的库,它可以在 Web 页面实时显示 Celery 任务执行者的状态、任务的状态等。flower 还提供了 REST API 用于第三方应用直接触发任务执行、获取任务执行结果等,这极大地扩展了 Celery 的应用范围,例如一个 Java 应用可以通过 flower 的 REST API 使用 Celery 的异步任务系统。
2. 参数说明
使用 Celery 涉及的参数配置较多,核心参数配置说明如表1所示。注意,参数名称要大写。
| 参数配置示例 | 配置说明 |
|---|---|
|
BROKER_URL = 'amqp://username:passwd@ host:port/虚拟主机名' |
消息中间件的地址,建议采用 RabbitMQ 的方式。 |
| CELERY_RESULT_BACKEND='redis://username:passwd@host:port/db' | 指定结果的存储地址。 |
| CELERY_TASK_SERIALIZER='msgpack' | 指定任务的序列化方式。 |
| CELERY_TASK_RESULT_EXPIRES=60*60*24 | 任务过期时间,即 Celery 任务执行结果的超时时间。 |
| CELERY_ACCEPT_CONTENT=["msgpack"] | 指定任务接受的序列化类型。 |
| CELERY_ACKS_LATE=True | 是否需要确认任务发送完成,这一项对性能有影响。 |
| CELERY_MESSAGE_COMPRESSION='zlib' | 压缩方案选择,可以是 zlib 或 bzip2,默认为没有压缩。 |
| CELERYD_TASK_TIME_LIMIT=5 | 规定完成任务的时间,在5秒内完成任务,否则执行该任务的任务执行者将被杀死,任务移交给父进程。 |
| CELERYD_CONCURRENCY=4 |
任务执行者的并发数,默认为服务器的内核数目,可以使用命令行参数-c指定数目。 |
| CELERYD_PREFETCH_MULTIPLIER=4 | 任务执行者每次从消息中间件预取的任务数量。 |
| CELERYD_MAX_TASKS_PER_CHILD=40 | 每个任务执行者执行多少任务会死掉,默认为无限。 |
Celery 支持多种的数据序列化方式,常见的数据序列化方式如表2所示。通常,为了保持跨语言的兼容性和速度,我们一般采用 msgpack 或 JSON 方式。
| 序列化方式 | 说明 |
|---|---|
| binary | 二进制序列化方式,Python 的 pickle 库默认的序列化方式。 |
| JSON | 支持多种语言,可用于跨语言方案,但不支持自定义的类对象。 |
| msgpack | 二进制的类 JSON 序列化方式,但比 JSON 方式的数据结构更小,运行速度更快。 |
| yaml | 表达能力更强,支持的数据类型比 JSON 方式多,但是 Python 客户端的性能不如 JSON 方式。 |
3. 基本使用
Celery 的使用过程很简单:- 先通过命令确定异步任务函数,生产者会把函数名和相关参数传给消息中间件;
- 然后通过命令启动 Celery,实现任务执行者对消息队列的监听。
下面我们使用 Redis 来展示,Redis 在使用的时候充当两个角色,一个是消息中间件,另一个是存储结果的数据库。
基本使用主要有如下5个步骤。
1) 创建项目celeryDemo。
2) 创建异步任务执行文件 celery_task,文件内容如代码清单3所示。
代码清单3:celery_task
# -*- coding: utf-8 -*-
# @Project : celeryDemo
# @File : celery_task.py
# @Date : 2023-08-26
import celery
import time
backend = 'redis://127.0.0.1:6379/1' # 设置Redis的1数据库来存放结果
broker = 'redis://127.0.0.1:6379/2' # 设置Redis的2数据库来存放消息中间件
cel = celery.Celery('test', backend=backend, broker=broker)
# 参数说明:第一个是Celery的名字,Celery和哪个项目相关就命名哪个
# 后面两个关键字参数用于指定消息中间件和结果存放位置。
@cel.task
def send_email(name):
print("向%s发送邮件..." % name)
time.sleep(5)
print("向%s发送邮件完成" % name)
return "ok"
@cel.task
def send_msg(name):
print("向%s发送短信..." % name)
time.sleep(5)
print("向%s发送短信完成" % name)
return "ok"
3) 使用命令启动Celery:
celery --app=demo worker -l INFO
4) 执行测试函数。建立一个文件,使用如下代码测试 Celery 异步函数:
from celery_task import send_email, send_msg
result1 = send_email.delay("张三")
print(result1.id)
result2 = send_email.delay("李四")
print(result2.id)
result3 = send_email.delay("王五")
print(result3.id)
result4 = send_email.delay("赵六")
print(result4.id)
注意,运行的结果不是异步函数的返回值,而是一个 ID,因为 Celery 会将函数进行异步处理,处理结果会存放至指定的数据库,而我们取值需要使用 ID。5) 异步获取结果如下:
from celery.result import AsyncResult
from celery_task import cel
async_result=AsyncResult(id="275f43a8-a5bb-4822-9a90-8be3feeb3b4", app=cel)
if async_result.successful():
result = async_result.get()
print(result)
# result.forget() # 将结果删除
elif async_result.failed():
print('执行失败')
elif async_result.status == 'PENDING':
print('任务等待中被执行')
elif async_result.status == 'RETRY':
print('任务异常后正在重试')
elif async_result.status == 'STARTED':
print('任务已经开始被执行')
说明:执行失败的效果是代码有错但是异步不停止,还是会执行获得 ID,但是当获取结果时,async_result.failed() 为真。如果要演示记得重启 Celery,否则修改不生效。
4. 进阶用法
除了基本用法,接下来,我们讲解3个进阶用法。1) 装饰器 @app.task 实际上将一个正常的函数修饰成一个 Task 对象,所以这里可以给修饰器加上参数来决定修饰后的 Task 对象的属性。
我们先让被修饰的函数成为 Task 对象的绑定方法,这相当于被修饰的函数成了 Task 的实例方法,可以调用 self 获取当前 task 实例的很多状态和属性。
2) 任务执行后,根据任务状态执行不同操作,这需要复写 Task 的 on_failure、on_success 等方法。示例如下:
# tasks.py
# 继承Task类
class MyTask(Task):
def on_success(self, retval, task_id, args, kwargs):
print 'task done: {0}'.format(retval)
return super(MyTask, self).on_success(retval, task_id, args, kwargs)
def on_failure(self, exc, task_id, args, kwargs, einfo):
print 'task fail, reason: {0}'.format(exc)
return super(MyTask, self).on_failure(exc, task_id, args, kwargs, einfo)
@app.task(base=MyTask)
def add(x, y):
return x + y
上面的代码通过 celery -A tasks worker --loglevel=info 运行任务执行者,根据任务状态执行不同操作,分别执行我们自定义的 on_failure 方法和 on_success 方法。3) 任务状态回调。
在实际场景中,获得任务状态是很常见的需求,当执行耗时时间较长的任务时,想获得任务的实时进度,需要自定义一个任务状态来说明进度并手动更新状态,从而告诉回调函数当前任务的进度。
三、封装示例
Celery 可以和很多程序结合,Flask 是 Python 中有名的轻量级同步 Web 框架,在一些开发中,可能会遇到需要长时间处理的任务,此时就需要使用异步的方式来实现,让长时间任务在后台运行,先将本次请求的响应状态返回给前端,不让前端界面卡顿,当异步任务处理好后,如果需要返回状态,再将状态返回。下面示例展示了一个长时间运行的任务,用户通过浏览器启动一个或者多个长时间运行的任务,通过浏览器页面可以查询执行中的所有任务的状态,页面会显示每一个任务的状态消息,当任务完成时会显示任务的执行结果。
图2是示例项目 myCelery 的项目结构。
图2:myCelery 的项目结构
在安装相关的依赖和 Redis 中间件后,结合 Flask 使用 Celery,主要有如下5步。
1) 配置并实例化 Celery 和 Flask 对象,并做配置绑定。Flask 与 Celery 整合不需要任何插件,Flask 应用使用 Celery 只需要初始化 Celery 客户端即可,示例如代码清单4所示。
代码清单4:celeryApp
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 6:49 下午
# @Project : myCelery
# @File : celeryApp.py
# @Version: Python3.9.8
from flask import Flask
from celery import Celery, platforms
from urllib.parse import quote
REDIS_IP = '172.21.26.54'
REDIS_DB = 0
# 若密码中出现了特殊的字符,建议用quote()进行转义,直接赋值会导致后续读取失败
PASSWORD = quote('hutong123456')
# 创建Flask的一个实例
flask_app = Flask(__name__)
# 配置Celery的backend和broker,只需要在初始化Flask应用时加入这行代码,将下面的配置信息写入应用的配置文件
# 使用Redis作为消息代理
flask_app.config['CELERY_BROKER_URL'] = 'redis://:{}@{}:6379/{}'.format(PASSWORD, REDIS_IP, REDIS_DB)
# 把任务结果保存在Redis中
flask_app.config['CELERY_RESULT_BACKEND'] = 'redis://:{}@{}:6379/{}'.format(PASSWORD, REDIS_IP, REDIS_DB)
platforms.C_FORCE_ROOT = True # 解决根用户不能启动Celery的问题
# CELERY_ACCEPT_CONTENT = ['application/json']
# CELERY_TASK_SERIALIZER = 'json'
# CELERY_RESULT_SERIALIZER = 'json'
# 创建一个Celery实例
celery_app = Celery(flask_app.name,
broker=flask_app.config['CELERY_BROKER_URL'],
backend=flask_app.config['CELERY_RESULT_BACKEND'],
include=['task', 'task2'])
celery_app.conf.update(flask_app.config)
celery_app.autodiscover_tasks()
if __name__ == '__main__':
pass
Celery 通过创建一个 Celery 类对象来初始化,传入 Flask 应用的名称、消息代理的连接 URL、存储结果的 URL 以及包含的 task 任务列表。URL 放在 flask_app.config 中的 CELERY_BROKER_URL 和 CELERY_RESULT_BACKEND 的键值。另外,Celery 的其他配置可以直接用 celery_app.conf.update (flask_app.config) 通过 Flask 的配置直接传递。
2) 用实例化的对象去关联执行任务的方法,通常通过 Python 的装饰器实现。任何作为后台异步任务的函数只需要用 @celery.task 装饰器装饰即可,即在需要异步执行的方法上使用 @celery.task 装饰器。示例如代码清单5所示。
代码清单5:task
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 9:58 上午
# @Project : myCelery
# @File : task.py
# @Version: Python3.9.8
from celeryApp import celery_app
import time
# 这里定义一个后台任务task,异步执行装饰器为@celery_app.task
@celery_app.task(bind=True)
def long_task(self):
total = 100
for i in range(total):
# 自定义状态state为waiting..,另外添加元数据meta,模拟任务当前的进度状态
self.update_state(state='waiting..', meta={'current': i, 'total': total, })
# 使用sleep模拟耗时的业务处理
time.sleep(1)
# 任务处理完成后,自定义返回结果
return {'current': 100, 'total': 100, 'result': 'completed'}
因为前面配置定义的 Celery 的实例化对象名称叫 celery_app,所以在装饰器的时候要用 @celery_app.task。对于这个任务,通过在 Celery 装饰器中添加 bind=True 参数,让 Celery 发送一个 self 参数到自身,并使用它(self)来记录状态更新。self.update_state() 调用 Celery 如何接受这些任务更新。
Celery 有一些内置的状态,如 STARTED、SUCCESS 等,也支持自定义状态。代码中使用一个叫作 PROGRESS 的自定义状态,还可以有一个附件的元数据,该元数据是字典类型,包含目前和总的迭代数以及随机生成的状态消息。客户端可以使用这些数据来显示进度信息。每迭代一次休眠一秒,以模拟正在做一些工作。当循环退出,返回一个字典,这个字典包含更新迭代计数器、最后的状态消息和结果。
Celery 中常见的任务状态如表3所示。
| 参数 | 说明 |
|---|---|
| PENDING | 任务等待中 |
| STARTED | 任务已开始 |
| SUCCESS | 任务执行成功 |
| FAILURE | 任务执行失败 |
| RETRY | 任务将被重试 |
| REVOKED | 任务取消 |
3) 制作Flask的视图,演示调用和触发任务,并查看结果。通过 Flask,在浏览器中触发调用任务并查看异步执行的结果,这需要添加路由视图,示例如代码清单6所示。
代码清单6:webFlask
# -*- coding: utf-8 -*-
# @Time : 2023/8/26 10:42 上午
# @Project : myCelery
# @File : webFlask.py
# @Version: Python3.9.8
from flask import jsonify, url_for
from celeryApp import flask_app
from task import long_task
# 通过在浏览器中输入ip:port/longtask触发异步任务
@flask_app.route('/longtask', methods=['GET'])
def longtask():
# 发送或触发异步任务,通过调用apply_async函数,生成AsyncResult对象
task = long_task.apply_async()
print('task id : {}'.format(task.task_id))
# task_id和id一样的
# print('task id : {}'.format(task.id))
# url_for重定向到taskstatus()
return jsonify({"msg": "success"}), 202, {'Location': url_for('taskstatus',
task_id=task.task_id)}
# 通过在浏览器中输入ip:port/status/<task_id>查询异步任务的执行状态
@flask_app.route('/status/<task_id>')
def taskstatus(task_id):
# 获取异步任务的结果
task = long_task.AsyncResult(task_id)
print('执行中的 task id :{}'.format(task))
# 等待处理
if task.state == 'PENDING':
response = {
'state': task.state,
'current': 0,
'total': 100
}
# 执行中
elif task.state != 'FAILURE':
print('task info : {}'.format(task.info))
# task.info 和 task.result是一样的
# print('task info : {}'.format(task.result))
response = {
'state': task.state,
'current': task.info.get('current', 0),
'total': task.info.get('total', 100)
}
# task中定义了执行成功后返回的结果包含result字符
if 'result' in task.info:
response['result'] = task.info['result']
else:
# 后台任务出错
response = {
'state': task.state,
'current': task.info.get('current', 0),
'total': 100
}
return jsonify(response)
if __name__ == '__main__':
# 运行Flask
flask_app.run()
在上述代码中,Flask 应用能够请求执行这个后台任务,如 task=long_task.apply_async(),不直接调用任务函数,而是通过 apply_async() 调用任务函数。其中,long_task() 函数就是在一个 worker 进程中运行的任务。使用 apply_async(),我们可以添加参数给 Celery,告诉 Celery 如何执行后台任务,一个有用的参数就是要求任务在未来的某一时刻执行。例如,这个调用将安排任务在大约1分钟后运行:
apply_async(args=[10, 20], countdown=60)
调用 apply_async() 后会返回一个 AsyncResult 对象,通过这个对象可以获取任务状态的信息,AsyncResult 对象的属性或函数如表4所示。| 属性或函数 | 具体含义 |
|---|---|
| state | 返回任务状态 |
| task_id | 返回任务ID |
| result | 返回任务执行结果,等同于调用get()方法 |
| ready() | 判断任务是否完成 |
| info() | 获取任务信息 |
| wait(seconds) | 等待N秒后获取结果 |
| successful() | 判断任务是否成功 |
正如我们所见,浏览器需要发起一个请求到 /longtask 来启动一个或多个任务。响应使用状态码 202 通常是在 REST API 中使用,用来表明一个请求正在进行中。
另外也添加了 Location 头,值为一个客户端用来获取状态信息的 URL。这个 URL 指向一个叫作 taskstatus 的 Flask 路由,并且通过动态的要素 task_id 来获取异步任务的执行状态。
在 Flask 应用中访问任务状态,路由 taskstatus 负责报告后台任务提供的状态更新。为了能够访问任务的数据,我们重新创建任务对象,该对象是 AsyncResult 类的实例,使用 URL 中的 task_id。
第一个 if 代码块是当任务还没有开始的时候(PENDING状态),在这种情况下暂时没有状态信息,需要手动制造一些数据。接下来,elif 代码块返回后台的任务的状态信息,任务提供的信息可以通过 task.info 获得。如果数据中包含键 result,则意味着这是最终的结果并且任务已经结束,需要把这些信息加入响应。最后,else 代码块是任务执行失败的情况,这种情况下 task.info 中会包含异常的信息。
4) 通过命令启动和验证。首先启动 worker 执行任务,命令如下:
celery -A celeryAPP.celery_app worker --loglevel=info
其中,参数-A后是我们创建的 Celery 的初始化实例对象名称,包含对应的任务,worker 表示该实例就是任务执行者。另外,该命令需要在项目工程目录下执行,即本示例的 myCelery 目录。Celery 任务启动成功如图3所示。
图3:Celery任务启动成功
在图3中,我们可以看到 transport 和 results 的地址信息,以及 tasks 下的两个任务。
其他常见的 Celery 命令:
# 后台启动worker进程,参数-l指定worker输出的日志级别 celery multi start worker_1 -A appcelery -l info # 重启worker进程 celery multi restart worker_1 -A appcelery -l info # 立刻停止worker进程,如果无法停止,则加上参数-A celery multi stop worker_1 # 任务执行完,停止 celery multi stopwait worker_1 # 查看进程数 celery status -A appcelery
若 Celery 的日志输出的配置,若想在任务中输出日志,最好的方法如下:
from celery.utils.log import get_task_logger
lg = get_task_logger(__name__)
@celery.task
def log_test():
lg.debug("in log_test()")
但是仅如此我们会发现所有的日志最后都出现在 shell 窗口的 stdout 中,所以必须在启动 Celery 的时候使用-f选项来指定输出文件,如下:
celery -A main.celery worker -l debug -f log/celery/celery_task.log &
然后,启动 Flask,调用异步任务和获取异步任务执行状态,我们只需要在 PyCharm 中运行 webFlask 程序即可,运行成功后如图4所示。图4:Celery 结合 Flask 启动
接下来,通过浏览器触发 longtask 模拟的耗时任务,如图5所示,在浏览器输入地址后,会直接返回代码中预定义的消息。另外,此时已经触发异步任务,若点击多次,则会产生多条任务。
图5:在浏览器中触发 longtask 模拟的耗时任务
5) 监控和查看后台异步任务执行情况。我们可以进入 Redis,查看队列任务,发现有4条,使用 get 命令可以查看具体某一条任务的执行状态,如图6所示。
图6:查看队列任务
我们也可以通过浏览器查看,异步任务的3个时刻的执行状态如图7、图8和图9所示,可以发现 current 的值是动态变化的。
图7:异步任务状态1
图8:异步任务状态2
图9:异步任务状态3
最后,通过 flower 可以统筹监控所有的任务队列情况,执行命令如下:
celery -A celeryApp.celery_app flower --port=5556 --basic_auth=admin:admin
结果如图10所示。图10:监控任务队列
执行成功后,在浏览器中输入 http://localhost:5556,输入用户名和密码(admin/admin)登录,任务消费者如图11,任务名称如图12所示。
图11:任务消费者
图12:任务名称